
Technology
How To Create Enterprise Value with Technology In B2B
In the industrial B2B world of manufacturing, distribution, wholesale, and industrial services, technology has shifted...

Google.com is the most widely used search engine in the world. In fact, as of December 2022, it’s also by far the most used website in the world, with over 92 Billion monthly visits, eclipsing YouTube in second place. Every day, billions of curious minds turn to Google in search of answers—ironically, that’s probably how you stumbled on this article. What a strange and remarkable web we weave!
But have you ever wondered how Google sifts through billions of web pages in mere seconds to bring you the most relevant search results? How does Google search work, really? It’s all thanks to the sophisticated and constantly evolving algorithm at the heart of the search giant.
In this edition of The Tech Behind, we’re diving deep into the inner workings of Google Search and decoding the complex technology that makes it all possible. From the crawling process to indexing and ranking, we’ll take you on a thrilling journey of discovery and explain how the Google search algorithm is able to deliver the most accurate and valuable information to users.
So, whether you’re a tech enthusiast, a marketer, or just curious about how Google Search works, get ready to discover the magic behind the world’s most popular search engine!
Before diving into how Google Search works, let’s see how we got here in the first place.
The history of Google Search can be traced back to 1996, when two PhD students at Stanford University, Larry Page and Sergey Brin, began working on a research project to improve how search engines ranked web pages. The goal was to create a search engine that could understand a query’s meaning rather than simply match keywords.
In 1998, Page and Brin founded Google Inc., and the company began offering its search engine to the public. The early version of Google Search was reasonably straightforward, consisting of a single text box for entering a query and a results list.
However, it was also incredibly practical, thanks to the unique ranking algorithm that the company had developed, known as PageRank. This algorithm was based on the idea that a web page’s importance could be determined by the number and quality of links pointing to it.
The more links a page had and the more authoritative and relevant the sites linking to it were, the higher it would rank in the search results. Relevance, in this case, refers to the relatability of the referring link with the concerned page. This algorithm proved very effective and helped Google quickly establish itself as the dominant search engine on the web.
Even today, PageRank is one of the most prevalent search engine algorithms that Google deploys to identify authoritative and reliable pages from millions of records of similar content in their repository.
In 1997, Google.com was finally registered as a domain, and in 1998, the first Google Doodle was created, including the iconic man behind the ‘O’ in the Google logo. Over the years, we’ve seen some phenomenally creative temporary logo updates from Google, a.k.a the Doodle, and here are 20 of the most clever ones, starting with the first one ever released.

In 1998, the Google search engine was officially launched, with over 26 million web pages in the first index, which grew to a staggering 1 Billion pages in 2000.
Google launched AdWords, now Google Ads, in 2001, which meant users started seeing relevant search ads at the top of the SERPs (Search Results Pages) before the ten blue links of organic listings.
One of Google’s most intuitive features, the spell-checking feature showing “Did you mean?” with corrected spellings, was also launched in 2001. Before this improvement, when users had typos in their search queries, Google would find pages with the same spelling errors, often leading to sub-optimal search results.
In July 2001, Google Images was created following Jennifer Lopez’s viral jungle print dress at the 2000 Grammy Awards. It quickly became the most searched query on Google, prompting Google to introduce image results in their SERPs.
Google Images has undergone several iterations of improvements and optimisations over the years. In 2011, the “search by image” function was added to enable users to upload images and find similar photos through the search engine.
In 2002, the first set of Google APIs was made available, allowing developers to integrate the search engine with their own software programs. At the time, Google APIs could query more than 2 Billion web documents from their index and be compatible with environments built using Java, Perl, and Visual Studio.
Later in 2002, Google launched its own News feature to provide real-time news on the go. Google News was able to go one step further later on by gathering links for a particular story in real time and grouping articles together based on the related story. This allowed users to access links and articles of various authors and publishers and gain perspective from all sides of the story.
Froogle (Frugal + Google), now known as Google Shopping, was the subsequent introduction to the search engine. With the online shopping trend starting to pick some pace, Google launched Froogle in late 2002, where users could search through products listed online by businesses.
To improve the quality of search results, Google updated its algorithm to incorporate synonyms of search queries in 2003. Before this update, the search engine would only list pages with the exact same words as in the query. So, for example, if you searched for “How to cook pizza without an oven?” you’d have most likely missed several other helpful resources such as “How to cook pizza at home?” or “How to cook pizza in a microwave?”.
In the same year, Google also implemented calculators into the search engine. This meant you’d get an answer every time you added a mathematical calculation you couldn’t do in your head, such as (147 X 568) as an example.
Fast forward to 2004, and “Google Local” was added to the search arsenal, signalling the beginning of the end for traditional yellow pages. Today, Google’s local listing results serve as a significant gateway for business contact information, combining standard business listings with current information such as Maps, directions, reviews, products, related websites, ratings and so on.
What If you could type as quickly as you could think? Or, have you ever struggled to find the right words when using the Google search engine? Enter, Autocomplete – an intuitive feature that automatically predicts your query in the search bar as you start typing. The Autocomplete feature was first launched as “Google Suggest” in 2004.
The helpfulness of this feature is undeniable, and Google reports that Autocompletes reduces typing by almost 25 per cent and estimates that it saves over 200 years of typing time per day! Those numbers are bonkers, to say the least.
Google’s autocomplete feature uses a combination of machine learning in conjunction with historical search data. Essentially Google analyses look at past search queries and match the text entered with the most common queries to determine “autocomplete predictions”. The user’s past search history, location, and trending searches at the time are also factored into the equation.
Google Maps was first launched in 2005 on desktop, and within a couple of months, satellite and directions were added to the experience with the product. Since its initial launch, Google Maps has evolved significantly and now offers a range of features beyond just mapping and navigation.
Some of the notable updates and improvements to Google Maps include:
In an attempt to make it easier for website owners to get their information on Google search, Google Sitemaps was released in 2005. This also helped Google better understand the organisation and structure of websites so that they could provide more accurate and relevant search results.
Initially, Google Sitemaps was a simple tool that allowed webmasters to submit an XML sitemap file to Google. This file contained information about the pages on a website, including the URL, last modification date, and page priority.
But over time, Google Sitemaps has evolved and incorporated new features and technologies, later rebranding as Google Webmaster Tools, and today it is known as Google Search Console.
In the same year, with mobile phone usage increasing, several websites started implementing mobile-friendly versions of their websites. As a result, Google developed a new XHTML-based search service that sent users searching from phone to the mobile version of websites they were looking for.
Over the years, Google has continued to develop and refine its search algorithm, incorporating new technologies and data sources to improve the accuracy and relevance of its results.
Some examples of these changes include the integration of Knowledge Graph in 2012, which provided users with more informative results, and the Hummingbird update in 2013, which improved the search engine’s ability to understand the meaning behind a query.
In addition to these major updates, Google has also introduced several features and tools to enhance the search experience for users, such as:
The Knowledge Graph integrates with Google’s search algorithms to provide users with information about a wide range of topics, including definitions, images, and related information.
Over time, the Knowledge Graph has evolved into an extensive database of billions of facts and information from materials from all over the internet. You’ll find this unique search result for queries that require a quick snapshot of structured, detailed information, such as “Who Is Elon Musk? Or “Who Is the PM of Australia?”

The PAA feature is powered by Google’s natural language understanding protocols, which analyse the user’s query and identify related questions that may also be of interest. The answers displayed in the PAA section are dynamically generated based on the information Google has indexed from various sources, such as websites, books, and other digital content.

Google Lens works by first taking an image of the object or text using a smartphone camera. The image is then analysed using computer vision algorithms to identify and recognise the objects and text in the picture. Google’s algorithms then compare the recognised objects and text to a vast database of information to determine their identity and provide relevant information about them. The information is then presented to the user in the form of a search result, which can include details such as the name of the object, its location, reviews, and more.
Google Lens can be used to recognise a wide range of objects, such as books, buildings, plants, animals, and more, and provides information about them in real time. It can also translate text, scan barcodes and QR codes, and search for similar images.
With the integration of these services into the search results, Google has become not just a web search engine but a one-stop shop for information, news, and entertainment.
Today, Google Search continues to be the most widely used search engine in the world, with billions of queries conducted every day. Its algorithm is considered one of the most advanced and sophisticated in the world, and the company continues to invest heavily in research and development to improve its results’ accuracy, relevance, and speed.
So, finally, after all this build-up, let’s tackle the question, we are all here to find answers to: How does Google search work? Google Search uses a complex algorithm to process and rank billions of web pages to provide the most relevant results to a user’s query. The process can be broken down into several stages, explained below.
The first step in the process is to discover new web pages and add them to Google’s index. This is done using automated software called “spiders or crawlers”, which follow links from one page to another and index the content they find.
Google’s crawlers go from one page to another and store information about what they find from all publicly available content. As the spider crawls a website, it makes a copy of the page and adds it to the search index.
Once a page has been discovered and crawled, the next step is to index its content. This involves analysing the text and other elements of the page, such as images and videos, and extracting meaningful information, such as keywords, to create an entry in Google’s index.
When a user enters a query into Google, the search engine uses advanced algorithms to match the query with the most relevant pages in its index.
The algorithm considers hundreds of ranking factors or signals, such as the relevance of the content, the number of quality backlinks pointing to the page, and the user’s location and browsing history.
Finally, Google returns the most relevant results to the user through a list of web pages. The results are ranked by relevance, with the most relevant pages appearing at the top of the list.
Google also uses various features to enhance the search experience for users, such as rich snippets, which provide additional information about the result, and Knowledge Graph, which provides a summary of the information related to the query. We’ll discuss more on this later. It’s also worth noting that Google’s algorithm is constantly evolving and improving, with new updates and changes being made regularly.
The company uses machine learning and artificial intelligence to process the data and the ranking of the results; this is why it can be challenging to understand how Google’s algorithm works and why it’s impossible to know all the ranking factors. Next, we will detail these individual stages to solidify your understanding of the overall process.
Google’s Search Index is a vast database of all the web pages that Google has discovered and stored on the internet. When Google crawls the web, it analyses each page, extracts the content and stores a copy of the web page in the index.
The index is updated continuously as Google crawls new and updated web pages. The size of Google’s Search Index is constantly growing and is estimated to contain trillions of web pages, making it one of the largest databases of information in the world.
In fact, Google reports that its Search Index has over hundreds of billions of web pages and is estimated to be over 100,000,000 GB in memory. The index is used to power Google’s search results, providing users quick access to information on a wide range of topics.
Google’s crawling and indexing process is a complex and constantly evolving system that involves several steps to discover, analyse, and store information about web pages on the internet. Below is a more detailed explanation of the process.
Google uses various methods to discover new and updated web pages, including sitemaps, links from other indexed pages, and a continuous crawling process. Once a web page is discovered, Google adds it to its list of pages to crawl.
Google’s crawler, also known as a “spider,” visits each web page on the list and extracts information such as the page’s content, its HTML code, and any links on the page.
The crawler also analyses various factors, such as the page’s relevance, authority, and user experience, which will later be used to determine its ranking.
The extracted information from each web page is then added to Google’s Search Index, a vast database of web pages that Google has crawled and stored. The index is constantly updated as new and updated web pages are crawled and analysed.
When a user enters a search query on Google, the search engine uses the information stored in the index to quickly match the keywords in the query with relevant web pages.
Google then uses various algorithms and ranking factors, such as relevance, authority, and user experience, to determine the ranking of each web page and return the most relevant and authoritative pages as search results.
Google regularly re-crawls web pages to ensure its index is up-to-date with the latest information. If a web page is updated, Google will re-crawl and re-index the page to reflect the changes. This can take anywhere from a few days to a few weeks.
Google’s crawlers learn how often content they’ve seen before changes and revisit and update their index as necessary. In contrast, new content is discovered when new links or information appear on those pages.
Google’s crawling and indexing process is a crucial component of the search engine and plays a key role in determining the relevance and ranking of web pages in response to user search queries.
The process is complex and constantly evolving as Google strives to improve its search results and provide users with the most relevant and authoritative information.
Google uses various algorithms and ranking factors to determine the relevance and ranking of web pages in response to user search queries. With so much information in their extensive library, it can be nearly impossible to sort them without having a proper ranking system in place.
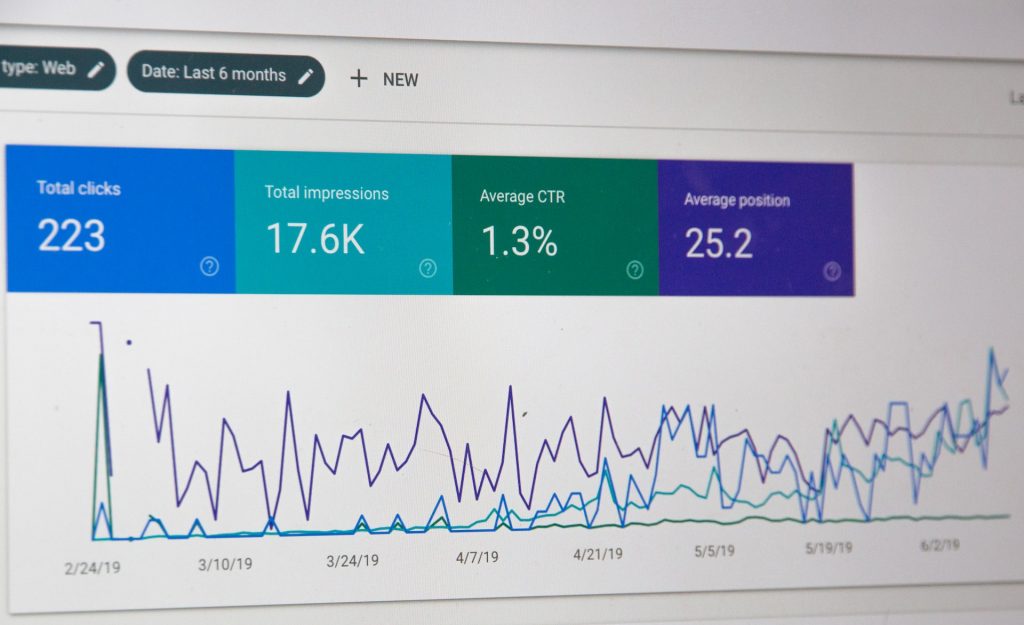
Google’s ranking algorithm sifts through countless records in its index to provide the most relevant and helpful results that match the searcher’s query and intent in a few seconds. The search algorithm deployed by Google assesses several signals, including the words in the search query, alignment of the query with pages in its index, authoritativeness and expertise of page sources, and the searcher’s location and settings.
Below, we’ll go over some of the main ranking factors that Google considers in its ranking algorithm.
The meaning of the query relates to the intent of the searcher. For Google to provide the most helpful answers, they need to fully understand what you’re looking for. Google uses their proprietary language models to decipher the relationship between the few words entered into the search box and the webpages that match with them the most.
To understand the intent of the search query, Google language models use pre-existing processes such as:
After determining the meaning of the query, Google’s ranking systems analyse the content in its index to find possible matches that might contain the information the searcher is looking for.
Google evaluates how well a web page matches the keywords in a user’s search query and considers the relevance of the content on the page. The most significant signal for relevancy is when there is an exact match between the keywords in the search query and the content on a web page. Keywords from a search query appearing on the title, URL, meta-description, and page headings point towards more relevancy.
The likelihood of such pages appearing towards the top of the SERP in the form of organic listings or even featured snippets increases drastically in such cases.
Besides assessing the types and number of keywords, the ranking systems also analyse the relevancy of the content in other ways, such as using aggregated and anonymised interaction data to determine the relevancy of similar search results from before to search queries. Such data is then transformed into signals that allow Google’s machine-learning algorithms to predict relevance more accurately in the future.
Using this system for determining relevancy, Google is able to provide better search results rather than solely relying on the keywords analysis method. Think about it for a second, if you search for “schools”, you don’t want to land on a page with the word “schools” written over it a thousand times, now do you?
That’s how the algorithm considers other relevant content besides the keyword, such as pictures, videos, reviews, and so on, containing the primary topic of the query.
The only drawback of this system as of now is that as it uses objective ranking signals, it fails to analyse subjective concepts such as the viewpoint or gist of a page’s information.
Google looks for high-quality, original content that provides value to users and evaluates the page’s overall relevance to the search query. After analysing the relevancy between the query and available content, Google’s ranking system looks towards prioritising the content that seems most helpful.
Google’s ranking systems use content quality signals such as demonstration of expertise, authoritativeness, and trustworthiness to assess the quality of content in webpages.
Google evaluates the authority and expertise of a website based on factors such as the number and quality of external links pointing to the site and the age of the domain. This ranking factor has proved to be a good sign that the information is trusted in the industry. Google’s Search quality evaluation process then uses aggregated feedback to further refine the system’s ability to assess content quality.
Google’s ranking systems also consider content usability as they believe that content that people find more accessible will provide more value and perform better on search engines.
Google also considers factors such as page loading speed, mobile responsiveness, and the overall user experience when evaluating the ranking of a web page.
Google considers the user’s location when returning search results and may prioritise web pages relevant to the user’s location. Furthermore, other user-specific factors such as previous search history and search settings are all assessed to provide the most valuable and relevant information specific to the searcher.
Google uses location information such as country and IP addresses to present content relevant and specific to that area. For example, the word “Football” would show differing results if you’re in Australia as opposed to the UK.
Search settings, such as preferred language or SafeSearch preferences, are also important ranking factors that Google considers to assess each search query.
Google’s ranking algorithms constantly evolve, and the company uses hundreds of ranking signals to determine the most relevant and authoritative web pages for each search query.
The algorithms also consider various factors, such as user behaviour, aggregate data used in machine learning, and real-time updates, to provide the most relevant and accurate search results.
Google’s search algorithm is a complex and constantly evolving system that involves several technologies and processes to determine the relevance and ranking of web pages in response to user search queries.
Here are some unique, in-depth insights into what happens with the algorithm and the technologies used to operate it on a continuum.
Google uses machine learning algorithms, such as neural networks and artificial intelligence, to process vast amounts of data and make real-time updates to its search algorithms. This allows Google to continuously improve its search results and provide users with the most relevant and authoritative information.
PageRank is one of Google’s original algorithms and was developed to evaluate the importance of web pages based on the number and quality of links pointing to the site. PageRank considers both the quantity and quality of links and the linking pages’ relevance to determine a web page’s ranking.
Hummingbird is a significant update to Google’s search algorithm introduced in 2013. It emphasises the meaning behind a user’s search query rather than just the individual keywords. It uses this information to return more relevant and accurate search results.

An important point to note with Google’s Hummingbird system is that it updated the algorithm to use conversational searches to understand the search query. This essentially means that longer, more in-depth questions result in better search results.
Google’s RankBrain system, an AI-based algorithm launched in 2015, is used to relate web pages with concepts, allowing Google to display pages that may not contain the exact words in the query. RankBrain uses machine learning algorithms to analyse large amounts of data, understand the relationships between words and phrases from a query, and establish alignment with a concept.
This allows Google to provide more relevant and accurate results for search queries, especially those that are longer, more complex or ones that have never been seen before. In addition, by better understanding the intent behind a user’s search query, RankBrain helps surface results that are more likely to match what the user is looking for.
BERT (Bidirectional Encoder Representations from Transformers) is a state-of-the-art machine learning model used by Google to process and understand natural language. BERT is used to understand the context better, and the meaning behind user search queries, allowing Google to provide more relevant and accurate search results.
With more than 15% of queries each day being new, Google needed BERT to address the challenges posed by the increasing number of natural language queries. This meant the Google Search algorithm required understanding the context and meaning of the query, regardless of the spelling and word combinations used.
Consequently, in 2018, Google launched the open-source neural network-based system BERT to train their natural language understanding models. BERT works by processing words in relation to the other words in a sentence instead of going one by one in order. Essentially, BERT can understand the complete meaning of a word in a search query by looking at the words that come before and after.
Before BERT, Google search used to work by focusing on the words in a search query that it thought were most important. The downside to this model was that small connective words in a sentence were ignored, and the overall meaning of the query needed to be understood entirely, resulting in subpar listings.
MUM, or Multitask Unified Model, is a recent AI-based system that Google added to its ranking system to understand complex queries better. MUM is programmed across 75 different languages, and as a multimodal system, it can realise information across multiple input formats, such as text and images.
MUM’s first actual application was during the COVID-19 pandemic when different vaccines’ names were dispersed worldwide. Using MUM, Google was able to identify over 800 different variations of vaccine names in over 50 languages very quickly. This information was then used to provide accurate information about COVID-19 vaccines worldwide based on their specific location and settings.
Google uses its cloud computing platform, Google Cloud, to store and process the vast amounts of data used in its search algorithms. As a result, Google Cloud provides the scalability and reliability needed to handle the billions of search queries processed daily by Google.
Modern search engines must understand more than just the words on a page, but what they actually mean to find the best one that matches what you’re looking for. So, for example, if you search for a “fast pitcher”, it will know you’re looking for an athlete. But if you search for a large pitcher, you will find options for your kitchen.
But how does Google make this differentiation? Machine learning is the driving force behind their comprehension of context and language.
Modern search engines have seen a rise in the use of machine learning to enhance their search algorithms. Machine learning allows search engines to process and analyse vast amounts of data in real-time and quickly update their algorithms.
Here are some ways machine learning is used in modern search engines:

Leveraging Google search can help businesses achieve their customer experience (CX) goals in several ways:
In conclusion, Google’s search algorithm is a complicated inter-connected blend of complimentary algorithms essential to the functioning of the world’s most popular search engine.
The algorithm can deliver relevant and accurate user results by constantly analysing and processing vast amounts of data. While the algorithm’s inner workings are continually refined and updated, understanding the core principles and technologies that drive it can help businesses and marketers optimise their websites and improve their search visibility.
As search technology continues to advance, it is vital to stay informed and up-to-date on the latest developments in the field to ensure a successful online presence.
All in all, Google Search is a remarkable feat of engineering, and it’s only getting more sophisticated as time goes on. Now that you know a little bit more about how it works, you can start thinking about how to use this knowledge to your advantage.
Book a discovery call with us today if you want to take your customer experience to the next level. We’ll show you how we can help you get the most out of your website and ensure that your customers always find what they’re looking for—fast.
February 03, 2023

